scrapy-redis分布式爬虫框架+示例
”scrapy-redis juzi1122 scrapy“ 的搜索结果
杂乱的集群 该Scrapy项目使用Redis和Kafka创建按需分布式抓取集群。 目标是在许多等待的蜘蛛实例之间分发种子URL,这些蜘蛛实例的请求通过Redis进行协调。 由于边界扩展或深度遍历而导致的任何其他爬网也会在群集中...
Scrapy的Playwright集成 该项目提供了一个Scrapy下载处理...要求Python 3.7以上Scrapy 2.0+ 剧作家0.7.0+安装$ pip install scrapy-playwright配置通过替换默认的http和https下载处理程序: DOWNLOAD_HANDLERS = { ...
python库。 资源全名:nimbus_scrapy-3.1.4-py2.py3-none-any.whl
Scrapy-2.3.0-py2.py3-none-any.whl 安装Scrapy所需要的资源,安装命令:pip target 本地资源路径
$ pip install scrapy-selenium 您应该使用python> = 3.6 。 您还将需要一种与Selenium。 配置 添加要使用的浏览器,驱动程序可执行文件的路径,以及将要传递给可执行文件的参数传递给scrapy设置: from shutil ...
Scrapy S3管道 Scrapy管道将项目存储到或存储桶中。 与内置不同,管道具有以下... $ pip3 install scrapy-s3pipeline[s3] 对于GCS用户: $ pip3 install scrapy-s3pipeline[gcs] 入门 用pip安装Scrapy S3 Pipelin
Scrapy框架需要安装的库 Scrapy-1.6.0-py2.py3-none-any.whl 和Twisted-18.9.0-cp37-cp37m-win_amd64.whl
scrapy-crawlera提供了与一起轻松使用的功能。 要求 Python 2.7或Python 3.4+ cra草 安装 您可以使用pip安装scrapy-crawlera: pip install scrapy-crawlera 文献资料 可在和docs目录中在线获取docs 。
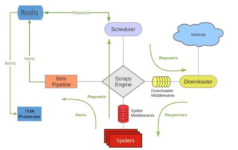
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。 2. 环境 系统:win7 scrapy-redis redis 3.0.5 python ...
====================== scrapy-project-template 基本的Scrapy项目的Cookiecutter兼容模板。 参见用法生成一个Scrapy项目:: cookiecutter https://github.com/arthuralvim/scrapy-project-template.git
scrapy-poet是scrapy-poet的Page Object模式实现。 scrapy-poet允许编写蜘蛛,其中提取逻辑与爬网分离。 使用scrapy-poet可以制作支持多个具有不同布局的站点的单个蜘蛛。 阅读以获取更多信息。 许可证是BSD 3...
Scrapy Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。...scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
只需将该项目放到不同的机器,简单配置一下redis /mysql 就可以运行,实现分布式抓取数据,需配置相同的环境scrapy/scrapy-redis/itemadapter/redis/mysql
粗糙分布Scrapy-Distributed是一系列组件,可让您轻松地基于Scrapy开发分布式爬虫。 现在! Scrapy-Distributed支持RabbitMQ Scheduler , Kafka Scheduler和RedisBloom DupeFilter 。 您可以非常轻松地在Scrapy的...
分布式爬虫scrapy-redis的搭建与运行
下载地址: Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 D 盘,解压后,将文件夹重新命名为 redis。 打开一个 cmd 窗口 使用 cd 命令切换目录到 C:...

Scrapy-1.5.0-py2.py3-none-any.whl可以用,放心xiasssasa
主要给大家介绍了关于scrapy-redis源码分析之发送POST请求的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用scrapy-redis具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧
scrapy-random-useragent, Scrapy中间件为每个请求设置一个随机的User Agent 随机 USER-AGENT由于你使用默认的USER-AGENT 或者一般的,你的nautilus蜘蛛会被服务器识别和阻塞?使用这里 random_useragent 模块并为每...

scrapy-redis简介 scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。 有如下特征: 1. 分布式爬取 您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合...
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据
Scrapy MongoDB队列基于MongoDB的scrapy组件,允许分布式爬网可用的Scrapy组件排程器复制过滤器安装来自pypi $ pip install git+https://github.com/jbinfo/scrapy-mongodb-queue 来自github $ git clone ...
Scrapy-Redis项目的搭建和部署 Scrapy-Redis项目的引入 scrapy是爬虫框架,但是只能在一台机器上运行程序。假如数据量特别多,一台机器就不够用了,那么就要多台机器一起配合使用,多台机器同时运行程序,共同爬数据...
一、Scrapy安装 1、首先确保一些依赖库以安装,命令如下: sudo apt-get install build-essential python3-dev libssl-dev libxml2-dev libxslt1-dev zlib1g-dev 2、利用pip安装scrapy,...二、Scrapy-Splash安装 ...

推荐文章
- Android Launcher 源码解析与启动流程_android launcher源码解析-程序员宅基地
- Unity显示360度全景照片_unity raw image显示全景图-程序员宅基地
- 简单LVS搭建_lvs本机搭建-程序员宅基地
- ctf-misc-buuctf刷题记录(初步)_ctf elf-程序员宅基地
- CSS3动画效果详解_css3 动画细说-程序员宅基地
- 浓度梯度与偏倚随机行走-程序员宅基地
- c语言程序设计历年考题,本科《C语言程序设计A》历年考题汇总-程序员宅基地
- Mac安装配置Sublime Text 3的方法(Python环境)_mac 安装配置sublime text-程序员宅基地
- finreport JS千分位-程序员宅基地
- POJ2488题解-程序员宅基地